TyT2019W43 - Heat Map
By Johanie Fournier, agr. in rstats tidyverse tidytuesday
October 24, 2019
Get the data
horror_movies <- readr::read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2019/2019-10-22/horror_movies.csv")
## Rows: 3328 Columns: 12
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (11): title, genres, release_date, release_country, movie_rating, movie_...
## dbl (1): review_rating
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Explore the data
summary(horror_movies)
## title genres release_date release_country
## Length:3328 Length:3328 Length:3328 Length:3328
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
##
## movie_rating review_rating movie_run_time plot
## Length:3328 Min. :1.000 Length:3328 Length:3328
## Class :character 1st Qu.:4.000 Class :character Class :character
## Mode :character Median :5.000 Mode :character Mode :character
## Mean :5.077
## 3rd Qu.:6.100
## Max. :9.800
## NA's :252
## cast language filming_locations budget
## Length:3328 Length:3328 Length:3328 Length:3328
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
##
Prepare the data
horror_movies$date<-as.Date(horror_movies$release_date, format="%d-%b-%y")
horror_movies$release_year<-year(horror_movies$date)
horror_movies$devise <- str_match(horror_movies$budget,"^[^0-9]+")[,1]
horror_movies$devise<-str_remove_all(horror_movies$devise,"[\\s]+")
horror_movies$budget_numeric <- as.numeric(gsub(horror_movies$budget, pattern = "[^0-9]",replacement = ""))
#Convertir toutes les devises en $US
conv_devise=data.frame("conversion"=c(1.290, 1.110, 0.760, 0.014, 0.680, 0.016,1,1,0.00085), "devise"=c("£", "€", "CAD", "INR", "AUD", "RUR ","$", NA,"KRW"))
#Sélectionner les 15 pays les plus présents dans les données
country<-horror_movies %>%
select('release_country') %>%
group_by(release_country) %>%
summarise(count=n()) %>%
top_n(15) %>%
select('release_country')
## Selecting by count
movie<-horror_movies %>%
filter(release_country %in% country$release_country) %>%
left_join(conv_devise, by="devise") %>%
mutate(budget_numeric_conv=budget_numeric*conversion) %>%
group_by(release_country, release_year) %>%
summarise(sum=sum(budget_numeric_conv,na.rm=TRUE), count=n()) %>%
mutate(sum=ifelse(sum==0, NA, sum)) %>%
mutate(prix_film=sum/count) %>%
drop_na(release_year)
## `summarise()` has grouped output by 'release_country'. You can override using the `.groups` argument.
#Calculer les moyennes
autres<-movie %>%
filter(!release_country=="USA") %>%
group_by() %>%
summarise(moy=mean(sum, na.rm=TRUE))
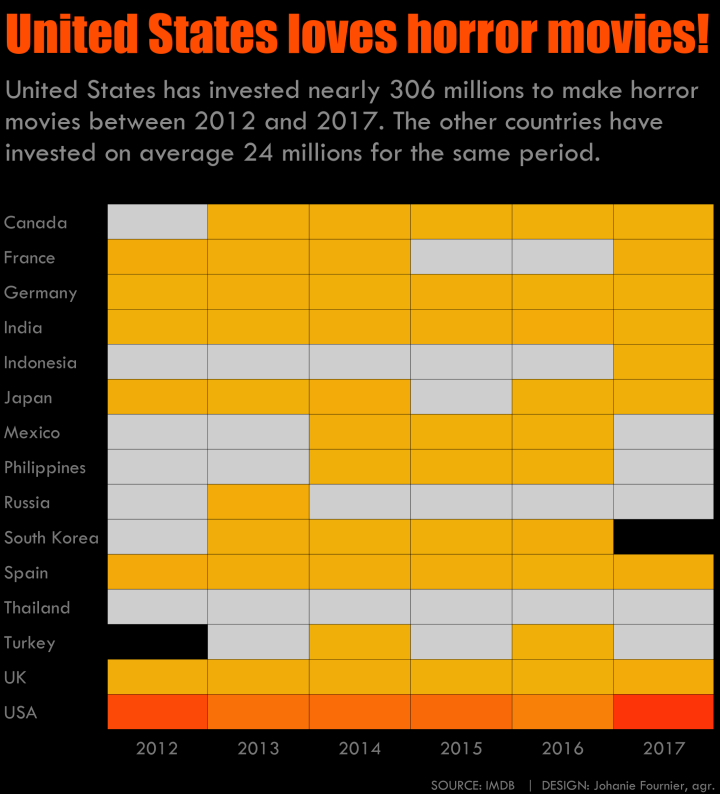
#Réponse: 24 244 745$US pour période de 5 ans
USA<-movie %>%
filter(release_country=="USA") %>%
summarise(moy=mean(sum, na.rm=TRUE))
#Réponse: 305 680 008$ en 5 ans!!
Line_US<-movie %>%
filter(release_country=="USA") %>%
mutate(sum=sum/1000000)
Line_other<-movie %>%
filter(!release_country=="USA") %>%
mutate(sum=sum/1000000)
Visualize the data
#Graphique
gg<- ggplot(data=Line_other,aes(x = release_year, y=sum, group=release_country))
gg <- gg + geom_line(size=2, color="#F5BB00")
gg <- gg + geom_line(data=Line_US,aes(x = release_year, y=sum, group=release_country),size=2, color="#FF4C00")
#retirer la légende
gg <- gg + theme(legend.position = "none")
#ajuster les axes
gg<-gg + scale_x_continuous(breaks=seq(2012,2017,1), limits=c(2012, 2017.2), expand = c(0,0))
gg<-gg + scale_y_continuous(breaks=seq(0,500,100), limits=c(0, 520), expand = c(0,0))
#modifier le thème
gg <- gg + theme(panel.border = element_rect(color="black",size=1, fill=NA),
panel.background = element_rect(fill="black"),
plot.background = element_rect(fill="black"),
panel.grid.major.x= element_blank(),
panel.grid.major.y= element_line(size=0.5, linetype="dotted",color="#8B8B8B"),
panel.grid.minor = element_blank(),
axis.line.x = element_line(size=1, color="#8B8B8B"),
axis.line.y =element_line(size=1, color="#8B8B8B"),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank())
#Créer le titre
couleur <- image_read('~/Documents/ENTREPRISE/Projets R/couleur/000000.png')
titre<- couleur %>%
image_scale("x20") %>%
image_background("#000000", flatten = TRUE) %>%
image_border("#000000", "720x190") %>%
image_annotate("United States loves horror movies!",
color = "#FF4C00", size = 102, location = "+10+5", font='Impact') %>%
image_annotate("United States has invested nearly 306 millions to make horror\nmovies between 2012 and 2017. The other countries have\ninvested on average 24 millions for the same period.",
color = "#8B8B8B", size = 58, location = "+10+150", font='Tw Cen MT')
- Posted on:
- October 24, 2019
- Length:
- 3 minute read, 481 words
- Categories:
- rstats tidyverse tidytuesday
- Tags:
- rstats tidyverse tidytuesday